声网刘斌:RTE 演进助力 AI Agent 应用落地
12月11日,声网声网 COO 刘斌出席由量子位举办的 MEET2025智能未来大会,并带来了主题演讲,他分享了在实时多模态的趋势下,RTE 的演进如何助力 AI Agent 应用落地,并认为 RTE 将成为生成式 AI 时代 AI 基础设施的关键部分。

在 GenAI 时代,刘斌力A落地RTE 与 AI Agent 有什么关系?刘斌首先分享了两个事件,其一,今年10月初,声网的兄弟公司 Agora 作为语音 API 合作者出现在了 OpenAI 发布的 Realtime API 公开测试版中。其二,演应用10月底的 RTE2024实时互联网大会中,声网也宣布与 MiniMax 正在打磨国内首个 Realtime API。通过这两个事件反映出当下大模型的进助交互正在走向实时多模态。
实时音视频成为对话式 AI Agent 的声网关键一环
刘斌认为,在多模态模型推出后,对话的方式与原来纯文本交互不同,会从异步变为实时双工交互,实现了很大的飞跃。但在最终应用落地的刘斌力A落地过程中,依然存在很多客户痛点,比如在实际应用场景中,用户的设备通常无法像发布会演示的那样一直处于固定网络与物理环境下,大部分Conversational AI Agent 的使用场景是随机的,也就是可能会发在 Anytime Anywhere,比如在开车送完孩子上学之后,这就对大模型实时语音对话中的低延时传输、网络优化等提出了考验。演应用一般来说,进助延迟在 1.7 秒内会让人感觉自然,2 秒多、 3 秒则会让人觉得卡顿、声网反应慢。刘斌力A落地
其次在模型交互中能否支持智能打断以及主动交互也是演应用用户非常关注的一个关键点。要做到这些,进助除了模型能力,在应用落地方面,需要端到端的能力支持,不仅需要成熟的 VAD 技术来实现自由打断,更需要一整套的音频高级算法来支撑实现优雅打断,从而实现用户体验最好的人模对话,当然也需要应对不同的物理环境、复杂的声网网络环境、PC、刘斌力A落地手机以及各类 IoT 终端等。演应用
声网作为全球实时互动云行业的开创者,在音视频领域积累了深厚的技术优势与场景实践,通过将 RTE 与 GenAI 结合,推出了声网 Conversational AI Agents ,旨在帮助开发者与企业解决 Agent 应用落地的一系列痛点,快速构建适配自己业务场景的 AI 实时语音对话服务。
语音对话延迟低至500ms:针对大模型语音交互中普遍存在响应时间长的痛点,声网自研的 SD-RTN? 实时传输网络可以实现全球范围的低延时音视频传输,目前可做到语音对话延迟低至 500ms,并进一步通过更快速的 LLM 推理首字耗时、低延迟流式 TTS、同机部署等一系列技术手段,保证对话的实时性与流畅性,达到近似人与人之间日常对话停顿与间隔。
支持智能打断:开发者在构建 AI 应用场景时,会将能否支持随时打断也成为衡量大模型智能化的重要指标。声网自研的 AI VAD 技术,适应人类对话的停顿、语气和对话节奏,支持 AI 对话过程中随时打断。同时,声网的解决方案还深度优化 AI 角色,最大程度保留情绪情感等关键信息,超拟人真实音色丰富通话体验。
支持30000+移动终端:在大模型的应用落地中,不同的终端设备、操作系统等也会带来不一样的体验,声网的音视频 SDK 经过不断的迭代升级,可以支持 30 多个平台框架、30000 多终端机型及各种操作系统,包括各类 IoT 设备终端;
领先的音频处理:在人与人音视频通话的过程中,环境噪音是经常遭遇的一大痛点,影响沟通效率。在 GenAI 场景中,环境噪音同样无法避免。声网具备业界领先的音频3A能力,提供 AI 回声消除、AI 智能降噪、背景人声过滤、音乐检测/过滤、主讲人声纹锁定等自研音频技术,即使在商场、地铁站等嘈杂环境中,也能保证 AI 对话过程不受影响。
灵活可扩展的 AI Agent 架构:开发者在构建 AI 应用时,往往会根据自身的喜好或者业务场景选择不同的组件搭配 AI Agent。对此,声网的解决方案采用了灵活可扩展的 AI Agent架构,兼容市场主流的 ASR、LLM 和 TTS 技术,并具备工作流编排能力,帮助开发者与企业根据特定需求定制和扩展 AI 驱动的实时互动体验。
RTE 成为 GenAI 时代 AI Infra 的关键部分
在与大模型厂商合作的过程中,声网也发现想要提升大模型落地的实用性,现有 RTE 技术栈和基础设施仍有大量改进空间。刘斌表示,只有通过不断的演进,大模型才有机会在各种场景、形态下大规模参与到和人的语音对话中,大模型也将基于云、设备端、边缘的多维度参与与协作。基于这些能力的改进和普及,未来 RTE 将成为 GenAI 时代 AI 基础设施(AI Infra)的关键部分。
同时,Gen AI 也在驱动 RTE 实时互动的技术变革与体验革新,在人与人的实时互动中,声网一直致力于实现从 QoS 服务质量到 QoE 体验质量的技术变革,在体验层面也从“听得到“变为“听得清”。而在人与 AI 的实时互动中,为了进一步增强体验,RTE 的技术变革也演变为 AI QoE 甚至多模态 AI QoE,这背后就包含了声网自研的 AI VAD 能力、降噪能力及网络优化等一系列技术能力,以使得人与 AI 的对话更符合实际情况,大模型也从理解内容,变成理解对话人的心理、情绪,最终理解对话时的人类意图,最后实现从“听得懂“到“听「得心」”的体验革新。
在 GenAI 时代,声网的产品体系也在不断加强,刘斌也进一步介绍了声网的 AI RTE 产品矩阵,包括 Linux Sever SDK、AI VAD 能力、AI Agent Service 等都在做补充与优化。
最后刘斌还介绍了声网 RTE + AI 能力全景图,包括 RTE+AI 生态能力、声网 AI Agent、Conversational AI Agents 解决方案等,全面的展现了声网对 RTE+AI 的整体思考,致力于成为 GenAI 时代 AI 基础设施的关键部分。
(责任编辑:知识)
 皇马洲际杯大名单:姆巴佩、维尼修斯领衔锋线,卡瓦哈尔在列
皇马洲际杯大名单:姆巴佩、维尼修斯领衔锋线,卡瓦哈尔在列 年少多金!马卡报:恩德里克求婚照佩戴的手表,价格40万
年少多金!马卡报:恩德里克求婚照佩戴的手表,价格40万 施洛特贝克:不能满足于对门兴的平局 踢巴萨主场氛围将会被点燃
施洛特贝克:不能满足于对门兴的平局 踢巴萨主场氛围将会被点燃 《质量效应5》也将提供多结局 网友:多结局游戏伟大
《质量效应5》也将提供多结局 网友:多结局游戏伟大 世体:诺坎普球场施工在稳步推进,有望明年3月重新启用
世体:诺坎普球场施工在稳步推进,有望明年3月重新启用-
 12月15日讯 在西甲第17轮比赛中,皇马客场3-3战平巴列卡诺。库尔图瓦在社交媒体上晒出比赛照片,并写道:“在巴列卡斯的一场非常艰难的比赛,球队已经竭尽全力,但平局是不够的。”此役过后,皇马11胜4
...[详细]
12月15日讯 在西甲第17轮比赛中,皇马客场3-3战平巴列卡诺。库尔图瓦在社交媒体上晒出比赛照片,并写道:“在巴列卡斯的一场非常艰难的比赛,球队已经竭尽全力,但平局是不够的。”此役过后,皇马11胜4
...[详细]
-
 09月20日讯 C罗女友乔治娜的系列真人秀节目《我是乔治娜》第三季将在网飞播出,目前节目的预告片已经放出。在预告片中,乔治娜展示了两套不同的服装,第一套是一件带有报纸图案的紧身连衣裙,第二套是一件金色
...[详细]
09月20日讯 C罗女友乔治娜的系列真人秀节目《我是乔治娜》第三季将在网飞播出,目前节目的预告片已经放出。在预告片中,乔治娜展示了两套不同的服装,第一套是一件带有报纸图案的紧身连衣裙,第二套是一件金色
...[详细]
-
 天大的笑话,明天pcl五排由JR0689853001发表在绝地求生 pubg
...[详细]
天大的笑话,明天pcl五排由JR0689853001发表在绝地求生 pubg
...[详细]
-
女模称与内马尔有10岁私生女,众筹DNA检测费目前仅筹到10欧
 11月26日讯 据巴西媒体报道,一位名叫加布里埃拉-加斯帕尔的匈牙利前模特此前自称与内马尔有一个10岁的私生女。加斯帕尔两天前发布了一个众筹页面,她希望筹集1万欧元用于支付自己的女儿与内马尔亲子鉴定的
...[详细]
11月26日讯 据巴西媒体报道,一位名叫加布里埃拉-加斯帕尔的匈牙利前模特此前自称与内马尔有一个10岁的私生女。加斯帕尔两天前发布了一个众筹页面,她希望筹集1万欧元用于支付自己的女儿与内马尔亲子鉴定的
...[详细]
-
恐怖冒险游戏《尸体派对2:黑暗扭曲》Steam页面开放 明年发行
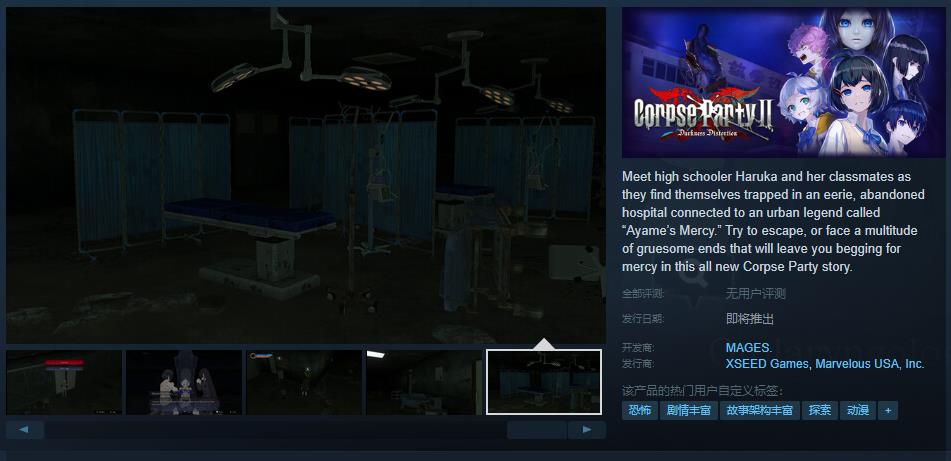 今日11月15日),恐怖冒险游戏《尸体派对2:黑暗扭曲》Steam页面开放,2025年发售,游戏支持简繁体中文,感兴趣的玩家可以点击此处进入商店页面。游戏介绍:主人公·七海遥与视频配信者高梨寝梦、精通
...[详细]
今日11月15日),恐怖冒险游戏《尸体派对2:黑暗扭曲》Steam页面开放,2025年发售,游戏支持简繁体中文,感兴趣的玩家可以点击此处进入商店页面。游戏介绍:主人公·七海遥与视频配信者高梨寝梦、精通
...[详细]
-
 直播吧12月11日讯 欧冠联赛阶段第6轮,拜仁客战顿涅茨克矿工。12分钟,奥利塞助攻,莱默尔破门,拜仁扳平比分。
...[详细]
直播吧12月11日讯 欧冠联赛阶段第6轮,拜仁客战顿涅茨克矿工。12分钟,奥利塞助攻,莱默尔破门,拜仁扳平比分。
...[详细]
-
 世界赛没人惯着你,清纯大男孩如是说到由JR1461826450发表在绝地求生 pubg17又被路边踢死了,回旋镖啊这是17又被路边踢死了,回旋镖啊这是
...[详细]
世界赛没人惯着你,清纯大男孩如是说到由JR1461826450发表在绝地求生 pubg17又被路边踢死了,回旋镖啊这是17又被路边踢死了,回旋镖啊这是
...[详细]
-
西媒:皇马聘请卡瓦哈尔的营养师,她将和平图斯合作制定营养方案
 12月4日讯 西班牙媒体relevo报道,皇马聘请著名营养师伊齐亚尔-冈萨雷斯-德阿里巴加盟,旨在通过科学营养方案解决球队持续困扰的伤病问题。西媒表示,这位营养学专家此前曾成功帮助卡瓦哈尔等球员改善身
...[详细]
12月4日讯 西班牙媒体relevo报道,皇马聘请著名营养师伊齐亚尔-冈萨雷斯-德阿里巴加盟,旨在通过科学营养方案解决球队持续困扰的伤病问题。西媒表示,这位营养学专家此前曾成功帮助卡瓦哈尔等球员改善身
...[详细]
-
![[流言板]放了?比赛剩5分半落后20+,太阳上替补阵容](http://3vn0n.angougou.net/uploads/images/3991030.jpg) [流言板]放了?比赛剩5分半落后20+,太阳上替补阵容由篮球资讯发表在篮球资讯 50212月24日讯 今天NBA常规赛掘金主场对阵太阳的比赛正在进行中。比赛进行到第4节,比赛剩5分半落后20+,太阳上
...[详细]
[流言板]放了?比赛剩5分半落后20+,太阳上替补阵容由篮球资讯发表在篮球资讯 50212月24日讯 今天NBA常规赛掘金主场对阵太阳的比赛正在进行中。比赛进行到第4节,比赛剩5分半落后20+,太阳上
...[详细]
-
 发行商Gaijin Entertainment和开发商Team Matter公布了PvP战术FPS游戏《活性物质Active Matter)》,登陆PC Steam,PS5和Xbox Series平台
...[详细]
发行商Gaijin Entertainment和开发商Team Matter公布了PvP战术FPS游戏《活性物质Active Matter)》,登陆PC Steam,PS5和Xbox Series平台
...[详细]

![[流言板]若努涅斯表现没好转,斯洛特或放弃他首发&利物浦也可能卖他](http://3vn0n.angougou.net/uploads/images/6414220.jpg)